
 Français
Français
Learning to Choose the Voice: Reinforcement Learning for Prompt Optimization in Cloning TTS
Level: Master 2
Supervisors: Meysam Shamsi (LIUM), Kévin Vythelingum (Voxygen), Marie Tahon (LIUM)
Host Laboratory: Laboratoire d’Informatique de l’Université du Mans (LIUM)
Location: Le Mans
Beginning of internship: Between January and March 2026
Contact: Meysam Shamsi (prénom.nom@univ-lemans.fr)
Application: Send a CV, a covering letter relevant to the proposed subject, your grades for the last two years of study and the possibility of attaching letters of recommendation to Meysam Shamsi or Marie Tahon before December 17, 2025
Context and objectives
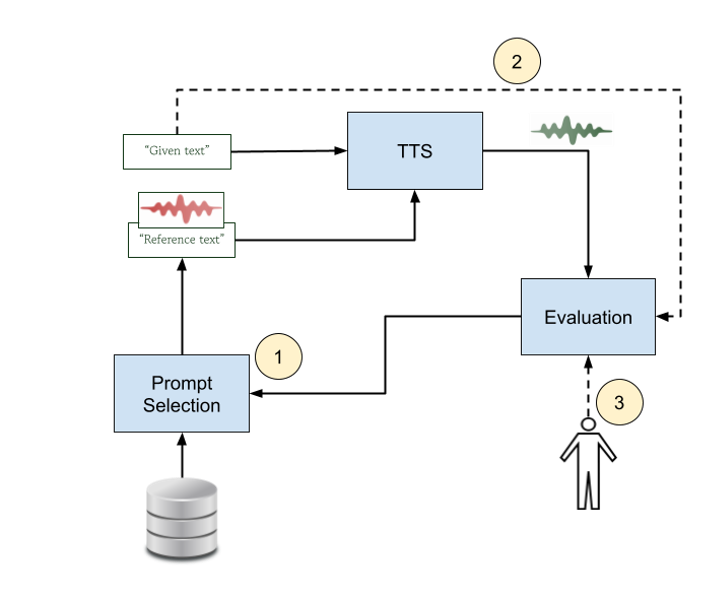
This project proposes a reinforcement-learning approach [1,2] for optimizing prompt selection in cloning-based text-to-speech systems such as F5-TTS [3,4]. In current voice-cloning workflows, the choice of prompt strongly affects the speaker’s characteristics and prosody of synthesized speech, yet the selection process is usually static or manual. The goal of this research is to develop an adaptive mechanism that automatically identifies the most suitable prompt for a given text by learning from predicted speech-quality scores.
The system builds on a pre-trained TTS model and a pre-trained synthetic quality prediction module [6,7] capable of estimating naturalness or similarity scores. During the initial phase, the reinforcement-learning agent receives text features as input and selects a prompt (text and corresponding speech signal) from a predefined prompt pool. The TTS model generates audio using the chosen prompt, and the evaluation module produces a quality score that acts as a reward. Through iterative interaction, the agent learns a prompt-selection policy that maximizes predicted speech quality, effectively discovering which prompts work best for different linguistic or stylistic contexts. This process enables a gradual improvement in prompt choice without modifying the underlying TTS model.
In the next stage (2), the evaluation module is enhanced to incorporate longer text context, allowing it to assess not only sentence-level acoustic quality but also coherence and consistency across extended passages. By conditioning the quality predictor on richer linguistic information, the system can better judge whether synthesized speech matches the semantic and stylistic intent of the input text. This context-aware evaluation strengthens the reward signal and leads to more stable, high-quality prompt selection across multi-sentence inputs.
In the long term (3), the synthetic quality predictor can be transformed into a preference-based model trained directly on listener feedback, a similar approach as [5]. Instead of relying solely on automatic metrics, the system would progressively align itself with subjective human judgments such as preferred tone, expressiveness, or clarity. The reinforcement-learning agent would then learn to select prompts not only for objective quality but also for user-specific preferences. This opens the possibility of personalized TTS generation, in which each listener receives speech tailored to their tastes through dynamic prompt selection.
Laboratories and supervisory team
The internship will be hosted at LIUM (Laboratoire d’Informatique de l’Université du Mans), where the intern will have full access to the laboratory’s computational infrastructure, including GPU-equipped servers. This internship continues the ongoing collaboration between LIUM and Voxygen, following their joint participation in the Blizzard Challenge 2025 [4], where both partners accumulated experience in training F5-TTS models, conducting evaluations, and analyzing TTS quality [7]. As a result of this prior collaboration, both the TTS module and the evaluation module, including the corresponding datasets, are already available, allowing the intern to focus directly on developing and validating the reinforcement learning based prompt-selection framework rather than building base components from scratch.
Candidate profil
Candidates motivated by artificial intelligence, enrolled in a master’s programme in computer science.
References
[1]. Chen, Chen, et al. “Enhancing zero-shot text-to-speech synthesis with human feedback.” arXiv preprint arXiv:2406.00654 (2024).
[2]. Chen, Jingyi. Reinforcement learning for fine-tuning text-to-speech diffusion models. MS thesis. The Ohio State University, 2024.
[3]. Chen, Yushen, et al. “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching.” Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics . 2025.
[4]. Mas, Pauline, et al. “VO2Lium: Voxygen and LIUM contribution for Blizzard 2025.” Blizzard Challenge. 2025.
[5]. Saget, Félix, et al. “Lifelong Learning MOS Prediction for Synthetic Speech Quality Evaluation.” Interspeech 2024. ISCA, 2024.
[6]. Cooper, Erica, et al. “Generalization ability of MOS prediction networks.” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.
[7]. https://git-lium.univ-lemans.fr/jsalt2025/wp1/tts4all_eval
![]()