
 English
English
Many un logiciel de combinaison de systèmes de traduction automatique statistique dont l’architecture est décrite dans le schéma suivant :
![]()
La combinaison se décompose en 3 étapes
- Les meilleures hypothèses des M systèmes sont alignées de manière incrémentale afin de générer M réseaux de confusion (chaque système est tout à tour considéré comme squelette).
- Ces réseaux de confusion sont ensuite connectés ensemble pour former un graphe. Le premier noeud de chaque réseau est connecté à un même noeud avec un arc ne supportant aucun mot mais avec une probabilité a priori assignée à ce backbone. Les noeuds finaux de chaque réseau sont connectés à un même noeud final avec une probabilité de 1.
- Un décodeur à jetons est utilisé pour décoder le graphe à l’aide d’un modèle de langage afin de produire les n-meilleures hypothèses de combinaison.
Le décodeur calcule les scores suivants : 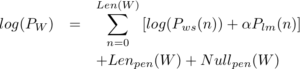 où
où
- Len(W) est la taille de l’hypothèse,
- Pws(n) est le score du n-ième mot,
- α est le facteur d’interpolation,
- Plm(n) est la probabilité linguistique du n-ième mot,
- Lenpen(w) est la pénalité sur la taille de l’hypothèse,
- Nullpen(w) est la pénalité sur le nombre d’epsilon-arcs traversés pour obtenir l’hypothèse.