
 Français
Français



Description
Within the framework of the French COMMUTE project (https://lium.univ-lemans.fr/en/projet-commute/), 30 hours of audio data in Central Kurdish language were collected, segmented, transcribed and translated into English. The main objective is to provide the scientific community with a spontaneous speech database, carefully annotated, polyvalent, for the development of speech technology dedicated to Kurdish oral and written language. The database consists of the following annotations:
- Manual segmentation: This data can be used to train automatic speech segmentation models,
- Speaker identity: This annotation is adapted to speaker processing tasks such as speaker diarization or verification,
- Kurdish transcription: Segmented audio files have been automatically transcribed with kurdish speech recognition system developed at LIUM (Le Mans University). All transcriptions have been manually reviewed to correct transcription errors. This data is suitable to train and evaluation automatic speech recognition models, especially in context of spontaneous speech.
- English translation: Kurdish transcriptions have been translated into English by native professional translators. The data is suitable for translation tasks such as speech-to-text, speech-to-speech, and text-to-text translation.
The dataset comes from three Kurdish media, collected with the kind agreement of authors.
- train : 9h10min from Voice of America (podcasts). This subcorpus mainly consists of political and cultural topics. A large amount of this data comes from hard channels, such as telephone. This subset comprises 19 podcasts and 4 951 segments,
- dev : 9h16min from Kurdistan24 (TV channel). This subset comprises 8 podcasts and 5 676 segments,
- test : 11h9min from the media network Rudaw, and contains 23 podcasts and 7 248 segments from various domains (economy, sport, art, science, etc.).
Data Format
For each long audio file, the following fields are provided in an accompanied TSV file with the same name as its WAV speech file:
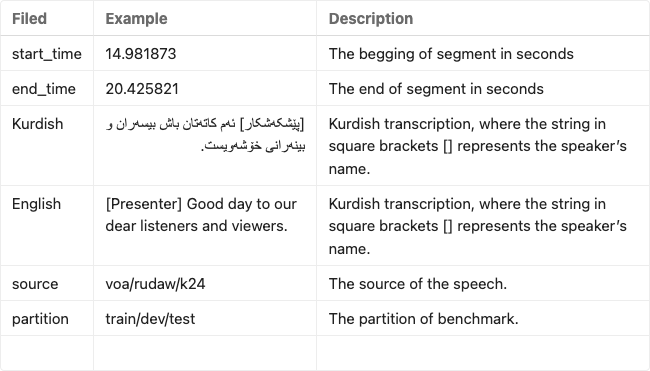
Download Data
The train, dev, and test parts of the Kurdish-Commute dataset can be downloaded from the following link.
https://lium.univ-lemans.fr/data-ext/iwslt2026/commute-kurdish-iwslt2026.zip
IWSLT 2026 challenge rules
- Complementary data
- Common Voice: All parts of Common Voice are allowed to be used.
Dataset: https://datacollective.mozillafoundation.org/datasets/cmj8u3oxx004lnxxbfr04zvrt - Giganet TTS : 10 hours of TTS data from one male speaker.
Dataset: https://huggingface.co/datasets/TTS4ALL/Kurdish_TTS
Documentation: https://www.sciencedirect.com/science/article/pii/S2352340924007194 - Asosoft Text Corpus:
Dataset: https://github.com/AsoSoft/AsoSoft-Text-Corpus,
Documentation: https://doi.org/10.1093/llc/fqy074 - Libraries
- Evaluation protocol
- BLEU and Chrf++ will be main evaluation metrics
- A baseline Whisper model is trained giving the following results on the dev and test parts:

- Baseline model
- Evaluation
The participants can use the provided resource for training any model in their proposed pipelines and solutions including ASR, TTS, S2TT, MT, LLM models.
The Asosoft library including normalization, g2p, number conversion, etc for Central Kurdish can be used.
Asosoft library https://pypi.org/project/asosoft/
The baseline Whisper v3 model can be downloaded from the following link. The baseline model is fine-tuned on the train part of Kurdish-Commute dataset.
The final evaluation will be done based on the BLEU score and ChrF++ scores on test partition. The Kurdish and English transcriptions of dev partition is already shared with participants in order to evaluate the performance of their systems. The transcriptions of the test partition will be shared later The evaluation link on the test set will be shared from this section later.
Important dates
The deadlines will be same as IWSLT.
Organizers:
- Mohammad Mohammadamini, LIUM, Le Mans University, France
- Marie Tahon, LIUM, Le Mans University, France
- Antoine Laurent, PyannoteAI & LIUM, Le Mans University, France
Contact person:
Mohammad Mohammadamini: mohammad.mohammadamini(@)univ-lemans.fr