
 English
English
Apprendre à choisir la voix : apprentissage par renforcement pour l’optimisation de Prompt dans le clonage TTS
Niveau: Master 2
Encadrement: Meysam Shamsi (LIUM), Kévin Vythelingum (Voxygen), Marie Tahon (LIUM)
Équipe d’accueil: Laboratoire d’Informatique de l’Université du Mans (LIUM)
Lieu: Le Mans
Début du stage : Entre janvier et mars 2026
Contact: Meysam Shamsi (prénom.nom@univ-lemans.fr)
Candidature: Envoyer votre CV, une lettre de motivation adaptée au sujet proposé, ainsi que le relevé de notes le plus récent, possibilité de joindre un avis ou des lettres de recommandations à Meysam Shamsi ou Marie Tahon (prénom.nom@univ-lemans.fr) avant le 17/12/2025
Contexte et objectifs
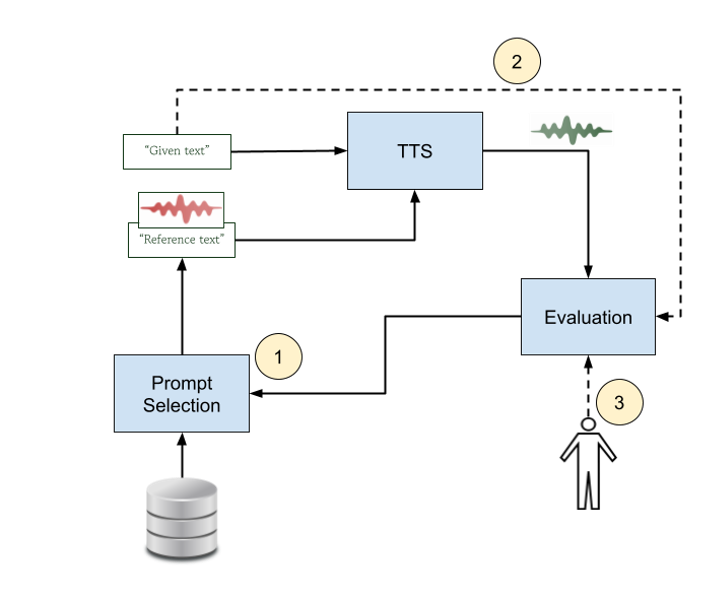
Ce projet propose une approche d’apprentissage par renforcement [1,2] pour optimiser la sélection des prompts dans les systèmes de synthèse vocale basés sur le clonage, tels que F5-TTS [3,4]. Dans les workflows actuels de clonage vocal, le choix du prompt influence fortement les caractéristiques du locuteur et la prosodie de la parole synthétisée, mais le processus de sélection est généralement statique ou manuel. L’objectif de cette recherche est de développer un mécanisme adaptatif qui identifie automatiquement le prompt le plus approprié pour un texte donné en apprenant à partir des scores de qualité vocale prédits.
Le système s’appuie sur un modèle TTS pré-entraîné et un module de prédiction de la qualité synthétique pré-entraîné [6,7] capable d’estimer des scores de naturalité ou de similarité. Au cours de la phase initiale, l’agent d’apprentissage par renforcement reçoit des caractéristiques textuelles en entrée et sélectionne un prompt (texte et signal vocal correspondant) dans un ensemble de prompte prédéfini. Le modèle TTS génère un fichier audio à partir de la commande choisie, et le module d’évaluation produit un score de qualité qui sert de récompense. Grâce à une interaction itérative, l’agent apprend une politique de sélection des commandes qui maximise la qualité vocale prédite, découvrant ainsi efficacement quelles commandes fonctionnent le mieux pour différents contextes linguistiques ou stylistiques. Ce processus permet une amélioration progressive du choix des commandes sans modifier le modèle TTS sous-jacent.
À l’étape suivante (2), le module d’évaluation est amélioré afin d’intégrer un contexte textuel plus long, ce qui lui permet d’évaluer non seulement la qualité acoustique au niveau de la phrase, mais aussi la cohérence et la cohésion sur des passages plus longs. En conditionnant le prédicteur de qualité à des informations linguistiques plus riches, le système peut mieux juger si la parole synthétisée correspond à l’intention sémantique et stylistique du texte d’entrée. Cette évaluation contextuelle renforce le signal de récompense et conduit à une sélection plus stable et de meilleure qualité des prompts dans les entrées comportant plusieurs phrases.
À long terme (3), le prédicteur de qualité synthétique peut être transformé en un modèle basé sur les préférences, entraîné directement à partir des commentaires des auditeurs, une approche similaire à celle décrite dans [5]. Au lieu de s’appuyer uniquement sur des mesures automatiques, le système s’alignerait progressivement sur les jugements subjectifs humains tels que le ton préféré, l’expressivité ou la clarté. L’agent d’apprentissage par renforcement apprendrait alors à sélectionner des prompts non seulement en fonction de la qualité objective, mais aussi en fonction des préférences spécifiques de l’utilisateur. Cela ouvre la possibilité d’une génération TTS personnalisée, dans laquelle chaque auditeur reçoit un discours adapté à ses goûts grâce à une sélection dynamique des prompts.
Laboratoire et équipe encadrante
Le stage se déroulera au LIUM (Laboratoire d’Informatique de l’Université du Mans), où le stagiaire aura pleinement accès à l’infrastructure informatique du laboratoire, y compris aux serveurs équipés de GPU. Ce stage s’inscrit dans la continuité de la collaboration entre le LIUM et Voxygen, suite à leur participation conjointe au Blizzard Challenge 2025 [4], où les deux partenaires ont acquis de l’expérience dans la formation de modèles F5-TTS, la réalisation d’évaluations et l’analyse de la qualité TTS [7]. Grâce à cette collaboration antérieure, le module TTS et le module d’évaluation, y compris les ensembles de données correspondants, sont déjà disponibles, ce qui permet au stagiaire de se concentrer directement sur le développement et la validation du cadre de sélection de prompt basé sur l’apprentissage par renforcement plutôt que de construire des composants de base from scratch.
Profil recherché
Candidat·e motivé·e par l’intelligence artificielle, inscrit·e en master informatique.
Références
[1]. Chen, Chen, et al. “Enhancing zero-shot text-to-speech synthesis with human feedback.” arXiv preprint arXiv:2406.00654 (2024).
[2]. Chen, Jingyi. Reinforcement learning for fine-tuning text-to-speech diffusion models. MS thesis. The Ohio State University, 2024.
[3]. Chen, Yushen, et al. “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching.” Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics . 2025.
[4]. Mas, Pauline, et al. “VO2Lium: Voxygen and LIUM contribution for Blizzard 2025.” Blizzard Challenge. 2025.
[5]. Saget, Félix, et al. “Lifelong Learning MOS Prediction for Synthetic Speech Quality Evaluation.” Interspeech 2024. ISCA, 2024.
[6]. Cooper, Erica, et al. “Generalization ability of MOS prediction networks.” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.
[7]. https://git-lium.univ-lemans.fr/jsalt2025/wp1/tts4all_eval
![]()