Français
FrançaisMultilingual Multimodal Continuous Representation for Human Language Understanding (M2CR)
Date: 06/2015 - 06/2019
Funding: Autres
Call: Chistera
Partners: MILA (Canada), CVC (Espagne)URL: http://m2cr.univ-lemans.fr/

Date: 06/2015 - 06/2019
Funding: Autres
Call: Chistera
Partners: MILA (Canada), CVC (Espagne)URL: http://m2cr.univ-lemans.fr/
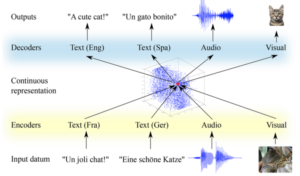
Communication is one of the necessary condition to develop intelligence in living beings. Humans use several modalities to exchange information: speech, written text, both in many languages, gestures, images, and many more. There is evidence that human learning is more effective when several modalities are used. There is a large body of research to make computers process these modalities, and ultimately, understand human language. These modalities have been, however, generally addressed independently or at most in pairs. However, merging information from multiple modalities is best done at the highest levels of abstraction, which deep learning models are trained to capture.
The M2CR project aims at developing a revolutionary approach to combine all these modalities and their respective tasks in one unified architecture, based on deep neural networks, including both a discriminant and a generative component through multiple levels of representation. Our system will jointly learn from resources in several modalities, including but not limited to text of several languages (European languages, Chinese and Arabic), speech and images. In doing so, the system will learn one common semantic representation of the underlying information, both at a channel-specific level and at a higher channel-independent level. Pushing these ideas to the large scale, e.g. training on very large corpora, the M2CR project has the ambition to advance the state-of-the-art in human language understanding (HLU). M2CR will address all major tasks in HLU by one unified architecture: speech understanding and translation, multilingual image retrieval and description, etc. The M2CR project will collect existing multimodal and multilingual corpora, extend them as needed, and make them freely available to the community. M2CR will also define shared tasks to set up a common evaluation framework and ease research for other institutions, beyond the partners of this consortium. All developed software and tools will be open-source. By these means, we hope to help to advance the field of human language.