
 English
English
Soutenance de thèse, Thomas Thébaud
Date : 21/10/2022
Heure : 9h45
Lieu : amphithéâtre de l’IC2, Le Mans Université
Titre : Attaques par reconstruction de données biométriques comportementales à l’aide d’alignements d’embeddings
Composition du jury :
- Najim DEHAK, Associate Professor, Johns Hopkins Whiting School of Engineering, Rapporteur
- Sébastien MARCEL, Professeur, IDIAP, Rapporteur
- Ruben VERA-RODRIGUEZ, Associate Professor, Universidad de Madrid, Examinateur
- Estelle CHERRIER, Maître de Conférence, ENSICAEN, Examinatrice
- Jean-François BONASTRE, Professeur, LIA, Examinateur
- Grigory ANTIPOV, Ingénieur en machine learning, Ubisoft, Examinateur
- Anthony LARCHER, Professeur, LIUM, Université du Mans, Directeur de thèse
- Gaël LE LAN, Chercheur, META FASTAI, Co-encadrant
- Simon BECOT, Orange Business Services, Invité
Accéder à la thèse en ligne.
Une thèse CIFRE en collaboration avec le LIUM et Orange Labs
Résumé :
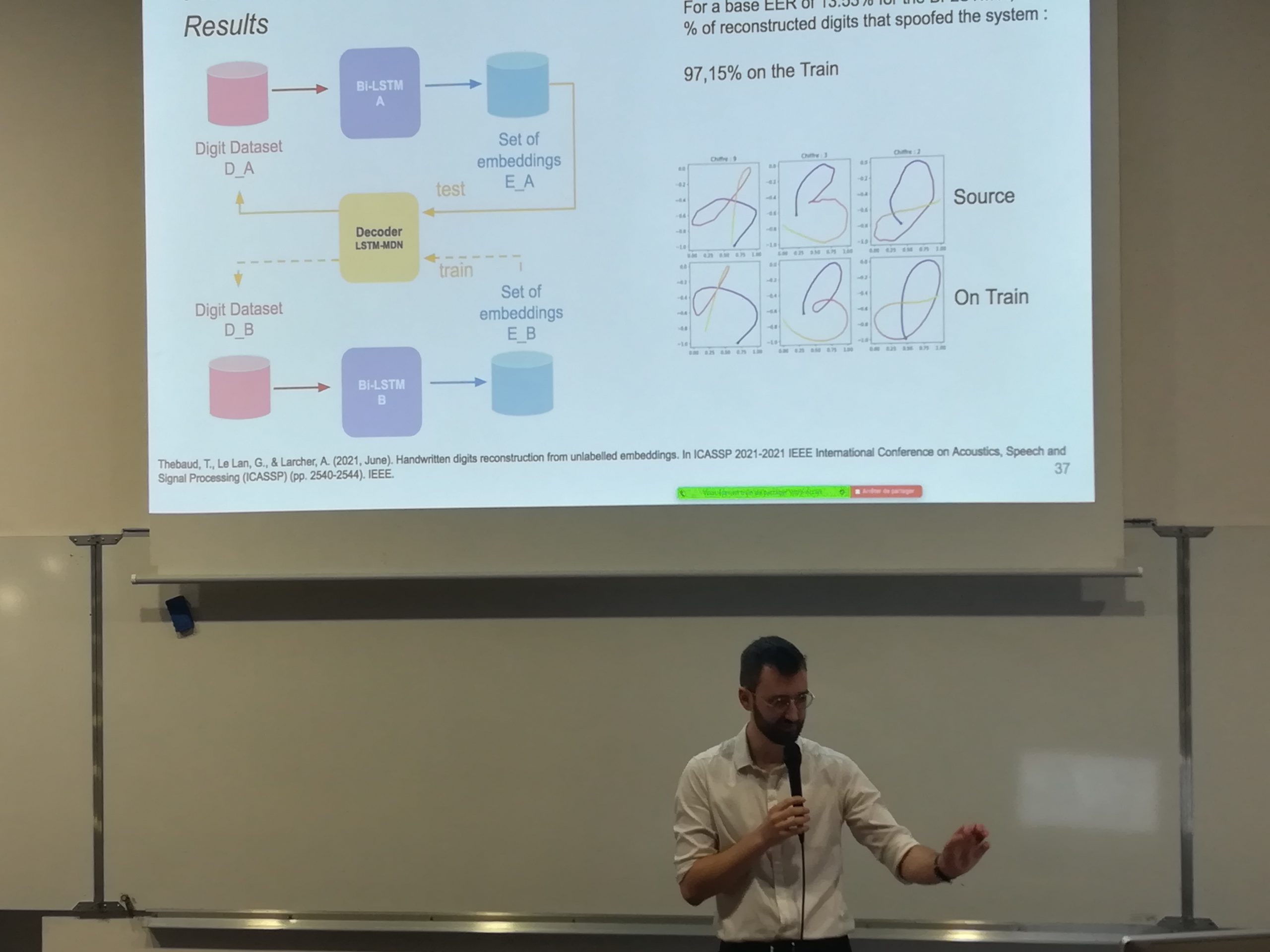
La protection des données personnelles est un devoir éthique et légal en Europe. Les systèmes d’authentification biométriques sont naturellement concernés : ils utilisent des vecteurs discriminants les utilisateurs extraits à partir de leurs données biométriques. D’un point de vue entre l’académique et l’industriel, cette thèse explore les vulnérabilités de ces vecteurs – embeddings – qui pourraient être utilisées pour voler des données personnelles et frauder un système d’authentification, appliquées à deux biométries comportementales : la parole et les chiffres manuscrits tracés à la main. Les attaques visant à reconstruire ou analyser des embeddings incluent généralement un accès à l’encodeur qui les a produit.
Nous avons proposé d’utiliser un alignement statistique non supervisé pour nous permettre, sans accès à l’encodeur, d’analyser un ensemble d’embeddings de chiffres manuscrits volés et de retrouver les chiffres qui leurs étaient associés. En affinant cet alignement et en utilisant un décodeur adapté, nous avons pu reconstruire les tracés de chiffres assez précisément pour frauder le système d’authentification qui les avait produits. La reconstruction de parole est plus complexe, car elle contiens une information linguistique très faiblement conservée dans les embeddings, nous avons donc utilisé un système de conversion de voix pour reconstruire des extraits de paroles assez précis pour frauder un système de vérification du locuteur. Nous avons aussi proposé une attaque sur un système de pseudo anonymisation, en utilisant des alignements supervisés et non supervisés sur les embeddings anonymisés produits par celui-ci, pour explorer ses limites.
Mots clés :
Vérification du Locuteur, Vérification du scripteur, Fraude, Authentification biométriques, Alignements statistiques supervisés et non supervisés, Reconstruction de données
![]()
![]()